

How We Test AI Coding Tools: Our Methodology & Review Process
Every recommendation on this site is backed by a structured testing process. This page explains exactly how we evaluate AI coding tools — what we test, how we score, and why you can trust our comparisons.
TL;DR
We test each tool hands-on across five real-world projects spanning different languages and complexity levels. We score on eight criteria, weight them by developer impact, and update every quarter as tools evolve. We have no paid placements — tools are ranked on merit, not marketing budgets.
Why Methodology Matters in This Niche
The AI coding tools market moves fast. A tool that ranked first in January may have changed its pricing, dropped a key feature, or shipped a game-changing update by April. Most comparison sites copy each other's listicles and never touch the actual software.
We do things differently. Before writing a word, every tool goes through our hands-on test suite. Our scores are reproducible: if you run the same tests, you should reach similar conclusions.
What We Test
The Five Test Projects
Each tool is evaluated against five standardized codebases that we maintain internally:
- Python data pipeline — a 3,000-line ETL script with async operations, type hints, and pytest coverage. Tests: autocomplete accuracy, refactoring suggestions, test generation.
- TypeScript monorepo — a Next.js + tRPC project with ~15 packages. Tests: cross-file context understanding, import resolution, multi-file edits.
- Rust CLI tool — a 1,200-line command-line application. Tests: borrow-checker awareness, documentation generation, error message interpretation.
- Legacy PHP refactor — a 5,000-line codebase with no type hints. Tests: code explanation quality, incremental refactoring, identifying dead code.
- Greenfield React app — built from scratch. Tests: scaffolding speed, component generation, inline documentation.
Every tool completes the same tasks on the same codebases. Results are logged in a shared scoring sheet before any editorial copy is written.
The Eight Scoring Criteria
We score each tool from 1 to 10 on eight dimensions. The final score is a weighted average.

| Criterion | Weight | What We Measure |
|---|---|---|
| Code quality | 25% | Correctness, idiomatic style, handling edge cases |
| Context understanding | 20% | Awareness across files, imports, project structure |
| Workflow integration | 15% | Setup friction, IDE/editor compatibility, keybinds |
| Pricing transparency | 15% | True cost including API usage, no hidden fees |
| Speed & reliability | 10% | Latency, uptime, rate-limit behaviour |
| Privacy & data handling | 10% | What gets sent to the cloud, opt-out options |
| Documentation & support | 3% | Quality of docs, community, response time |
| Free tier value | 2% | How useful the tool is before paying |
Why these weights? Code quality and context understanding account for 45% of the score because they directly determine whether the tool ships working code. Workflow integration and pricing transparency follow at 30% because the best tool in the world is useless if it disrupts your flow or costs 3× what you expected.
Our Testing Process, Step by Step
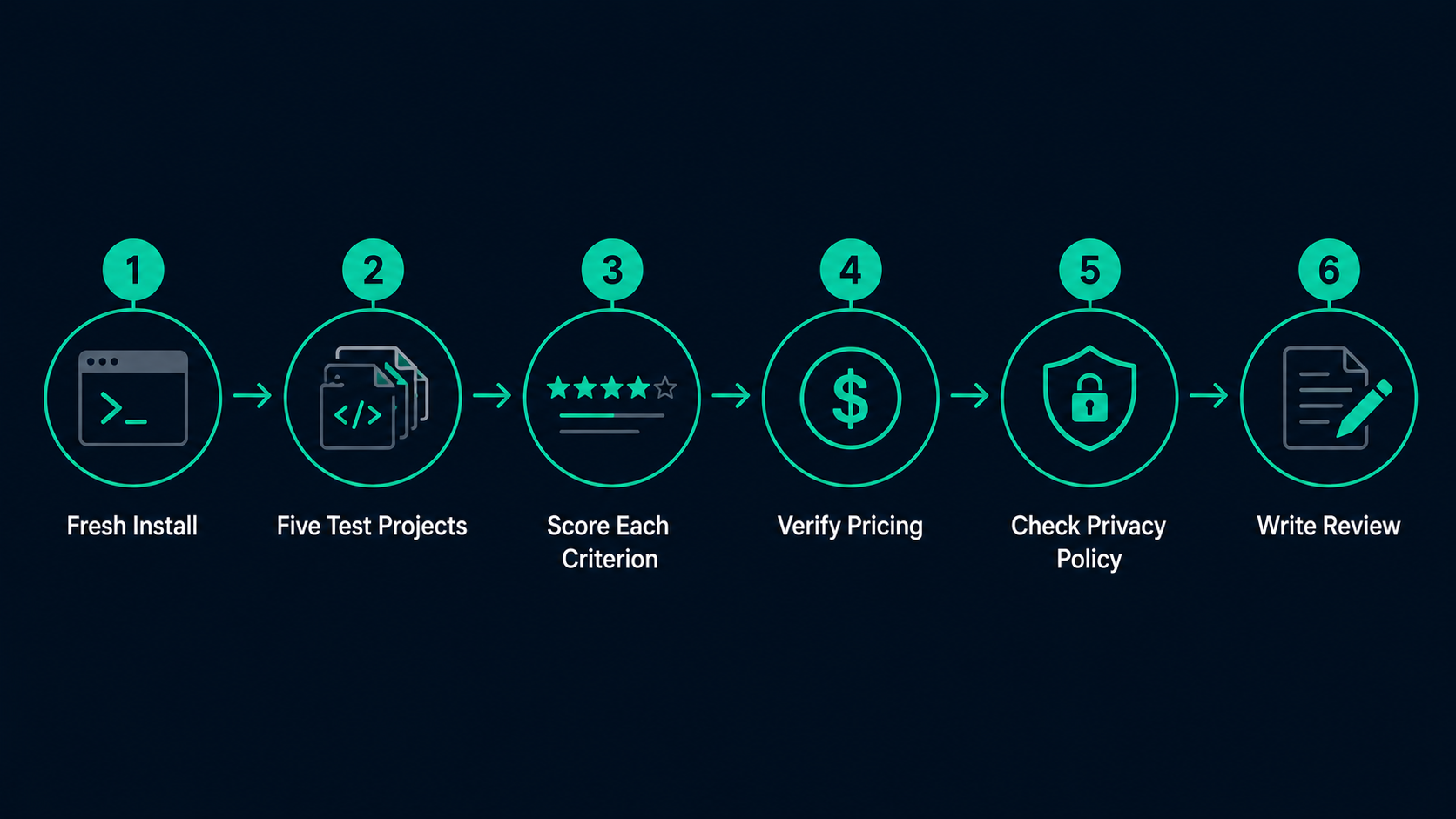
Step 1: Fresh install on a clean machine
We install each tool from scratch on a clean macOS 14 environment. We document every configuration step, including where the setup is unclear or painful. First-run experience counts.
Step 2: Run the five test projects
Each tester completes a defined task list per project. Tasks are identical across tools. We log completions, failures, and partial successes in a structured spreadsheet. Testers are not told each other's scores until the test is complete.
Step 3: Score each criterion independently
Scores are assigned per criterion before calculating the weighted total. This prevents the "halo effect" — where a tool that impresses in one area gets inflated scores everywhere else.
Step 4: Verify pricing claims
We check vendor pricing pages, look for hidden API costs, and test actual usage patterns to calculate a realistic monthly bill for three usage profiles: solo developer (light), full-time engineer (moderate), and power user (heavy).
Step 5: Check privacy policies
We review what data each tool sends to its servers, whether code is used for model training, and whether opt-out is available. We flag any discrepancies between marketing claims and actual policies.
Step 6: Write the review
Only after steps 1–5 are complete does the editorial copy get written. The score is not adjusted to match the narrative — the narrative reflects the score.
What We Don't Do
We don't accept paid placements. Tools cannot pay to appear in our rankings, reviews, or "best of" lists. Some tools have affiliate programmes — where we earn a commission if you sign up through our link. This is disclosed in every article. Affiliate relationships never affect scores or ranking positions.
We don't test on vendor-provided environments. All tests run on our own machines with our own accounts.
We don't use vendor-provided benchmark numbers. We run our own tasks and report our own results.
We don't treat all tools equally for long. We prioritise testing tools that have significant user bases or that appear frequently in developer community discussions (Reddit, Hacker News, GitHub). Obscure tools with no users get lower testing priority.
How Often We Update
The AI coding tools market changes monthly — sometimes weekly. We follow this update schedule:
- Quarterly full reviews — every three months, we re-run the full test suite on all tools in active comparison articles.
- Pricing updates — we check pricing pages monthly and update tables within 48 hours of a confirmed change.
- Feature updates — major feature releases (new model support, agentic capabilities, IDE integrations) trigger an immediate partial re-review of affected criteria.
- Article freshness stamps — every article shows a "Last tested" date so you always know how current the information is.
Who Runs These Tests
Our reviews are written by working software engineers — people who use AI coding tools in their daily work, not content writers following a template. Author bios are linked on every article.
We are not affiliated with Anthropic, the makers of Claude. Despite the domain name referencing Claude Code, this site covers all major AI coding tools impartially.
Frequently Asked Questions
Do you test every tool on this site? We test all tools featured in comparison articles and "best of" lists. Directory listings may include tools we haven't tested yet — these are clearly marked as unlisted/untested.
Can I submit my tool for review? Yes. Use the "Add your tool" link in the navigation. Submission is free. Being listed does not guarantee a review, and being reviewed does not guarantee a positive score.
What if a tool has changed since your last review? Check the "Last tested" date on the article. If it's more than 90 days old and you've noticed significant changes, use the contact form to flag it — we'll prioritise a re-test.
Do your affiliate links cost me anything extra? No. Affiliate commissions come from the vendor's budget, not from your subscription price.
Can I reproduce your tests? Yes. Our test task lists are described in enough detail that you can replicate the core workflow on your own codebase. We believe in reproducible evaluation methodology.
Contact & Corrections
Found an error? Know of a tool update that makes our review outdated? We want to hear about it. Accuracy matters more to us than being right.
Use the contact form or reach out via the channels listed in the site footer.
This methodology page was last updated in May 2026.